图像&文本的跨模态相似性比对检索【支持40种语言】
本例子提供了通过文本搜图片的能力展示(模型本身当然也支持图片搜文字,或者混合搜索)。
主要特性
- 底层使用特征向量相似度搜索
- 单台服务器十亿级数据的毫秒级搜索
- 近实时搜索,支持分布式部署
- 随时对数据进行插入、删除、搜索、更新等操作
背景介绍
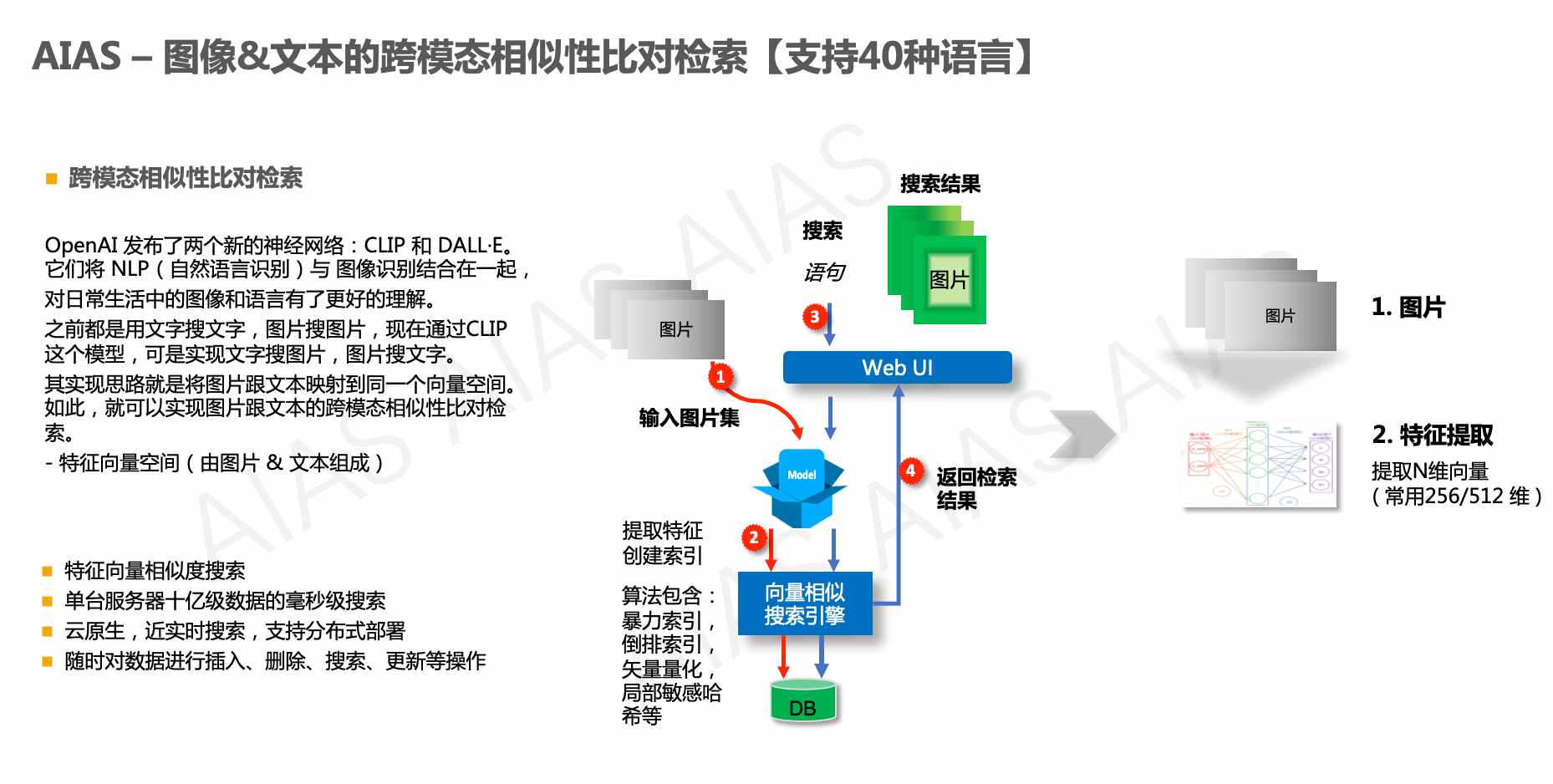
OpenAI 发布了两个新的神经网络:CLIP 和 DALL·E。它们将 NLP(自然语言识别)与 图像识别结合在一起,对日常生活中的图像和语言有了更好的理解。 之前都是用文字搜文字,图片搜图片,现在通过CLIP这个模型,可是实现文字搜图片,图片搜文字。其实现思路就是将图片跟文本映射到同一个向量空间。如此,就可以实现图片跟文本的跨模态相似性比对检索。
- 特征向量空间(由图片 & 文本组成)

CLIP - “另类”的图像识别
目前,大多数模型学习从标注好的数据集的带标签的示例中识别图像,而 CLIP 则是学习从互联网获取的图像及其描述, 即通过一段描述而不是“猫”、“狗”这样的单词标签来认识图像。
为了做到这一点,CLIP 学习将大量的对象与它们的名字和描述联系起来,并由此可以识别训练集以外的对象。
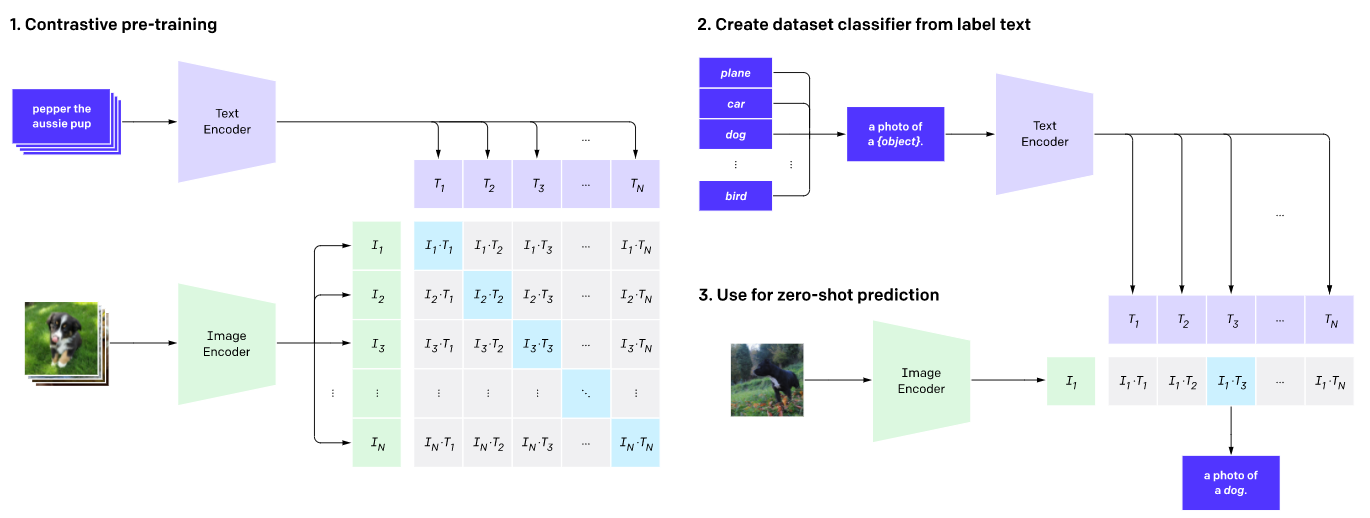 如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。
然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。
然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
支持的语言列表:

功能介绍
- 以图搜图:上传图片搜索
- 以文搜图:输入文本搜索
- 数据管理:提供图像压缩包(zip格式)上传,图片特征提取
1. 图片上传
1). 点击上传按钮上传文件.
2). 点击特征提取按钮.
等待图片特征提取,特征存入向量引擎。通过console可以看到进度信息。

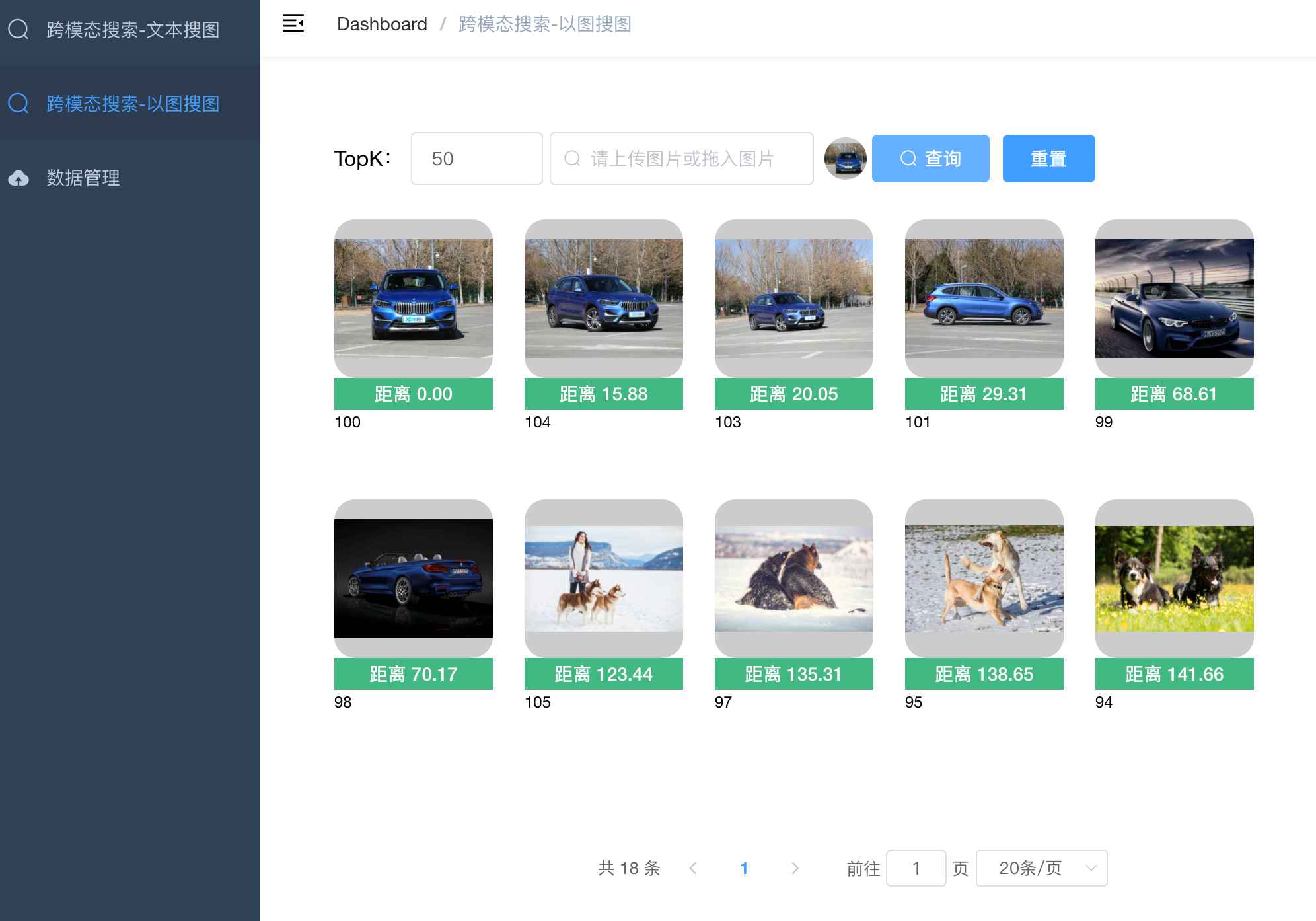
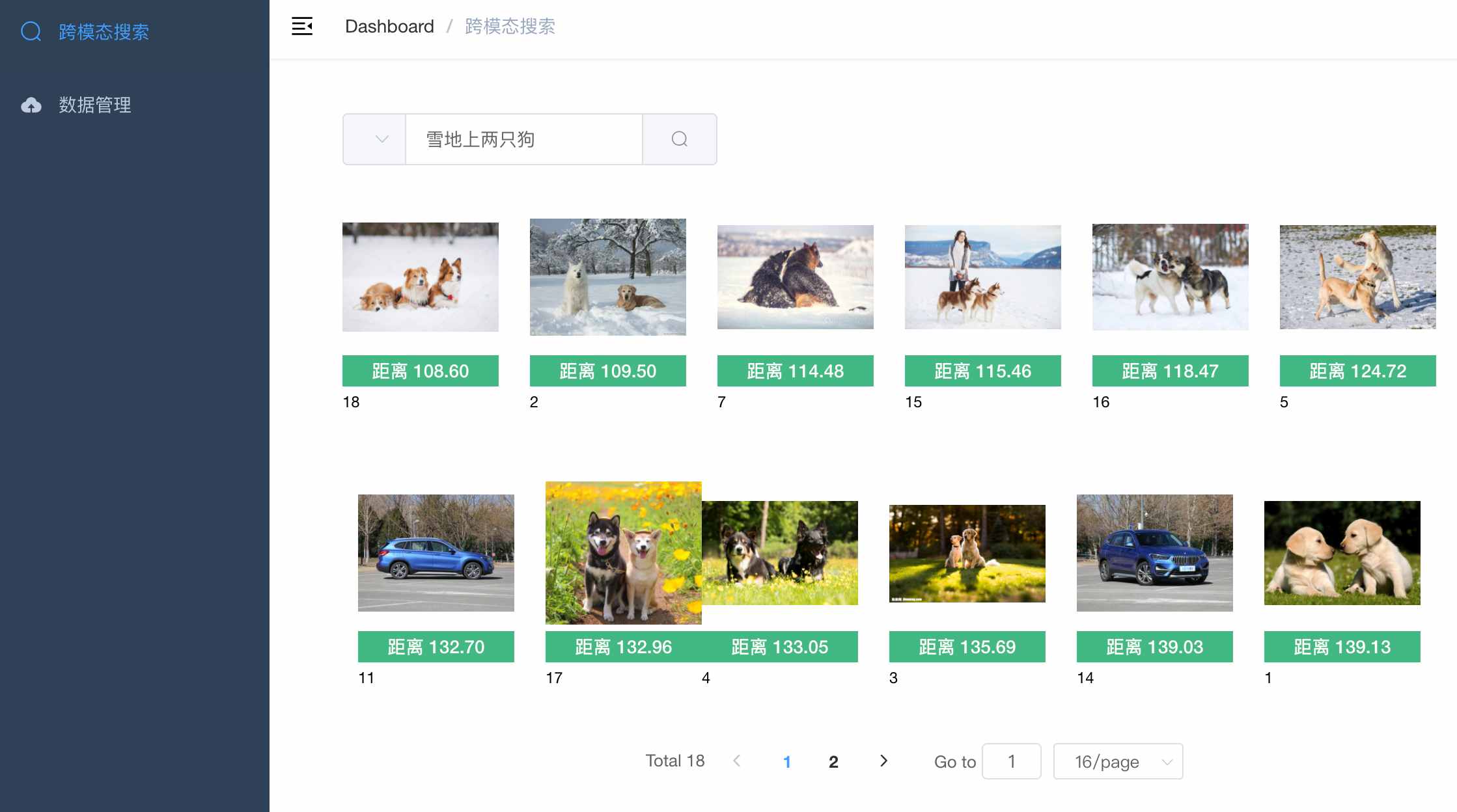
2. 跨模态搜索 - 以文搜图
输入文字描述,点击查询,可以看到返回的图片清单,根据相似度排序。
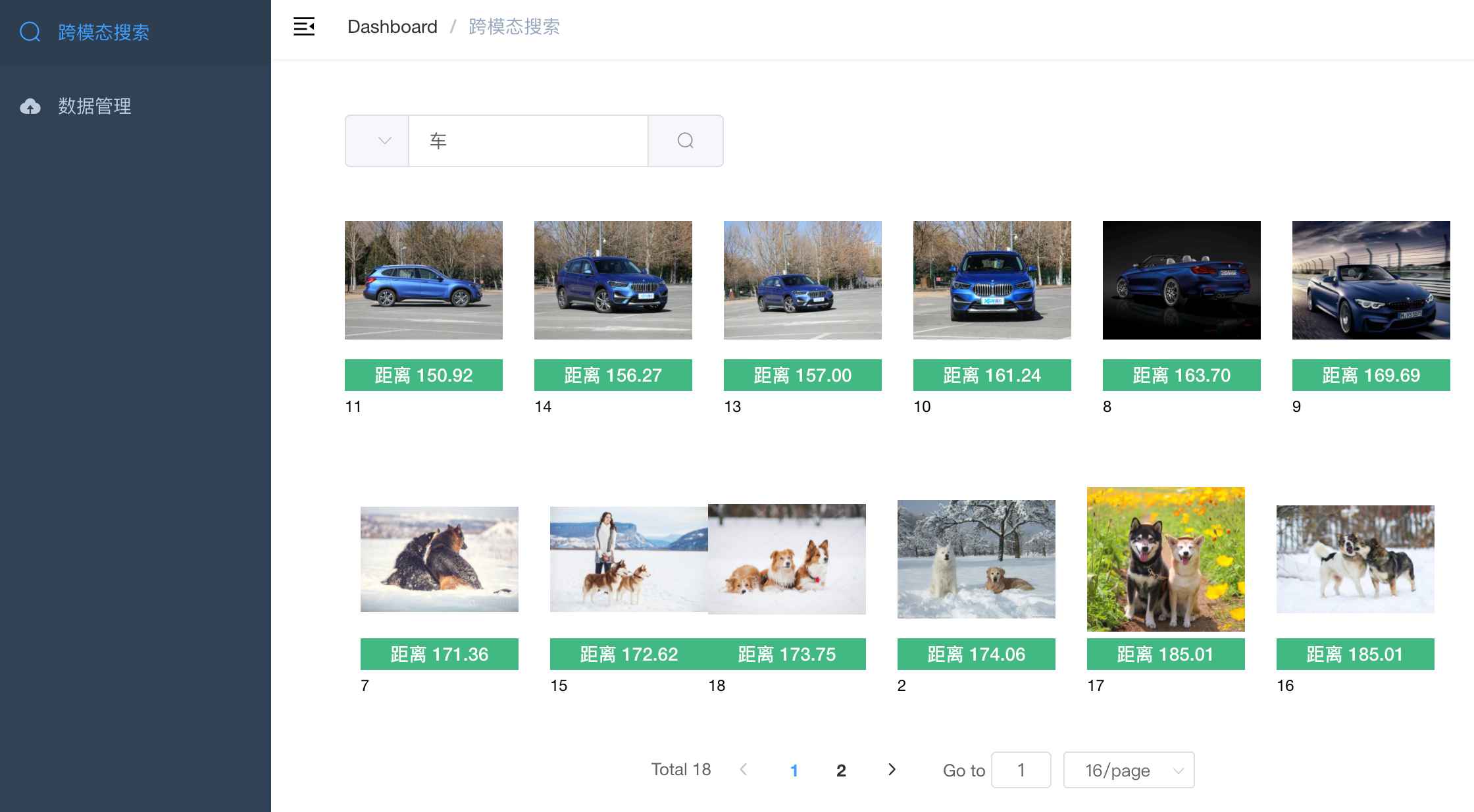
- 例子1,输入文本:车
- 例子2,输入文本:雪地上两只狗
3. 跨模态搜索 - 以图搜图