图像&文本的跨模态相似性比对 SDK【支持40种语言】
背景介绍
OpenAI 发布了两个新的神经网络:CLIP 和 DALL·E。它们将 NLP(自然语言识别)与 图像识别结合在一起,
对日常生活中的图像和语言有了更好的理解。
之前都是用文字搜文字,图片搜图片,现在通过CLIP这个模型,可是实现文字搜图片,图片搜文字。
其实现思路就是将图片跟文本映射到同一个向量空间。如此,就可以实现图片跟文本的跨模态相似性比对检索。
- 特征向量空间(由图片 & 文本组成)

CLIP,“另类”的图像识别
目前,大多数模型学习从标注好的数据集的带标签的示例中识别图像,而 CLIP 则是学习从互联网获取的图像及其描述,
即通过一段描述而不是“猫”、“狗”这样的单词标签来认识图像。
为了做到这一点,CLIP 学习将大量的对象与它们的名字和描述联系起来,并由此可以识别训练集以外的对象。
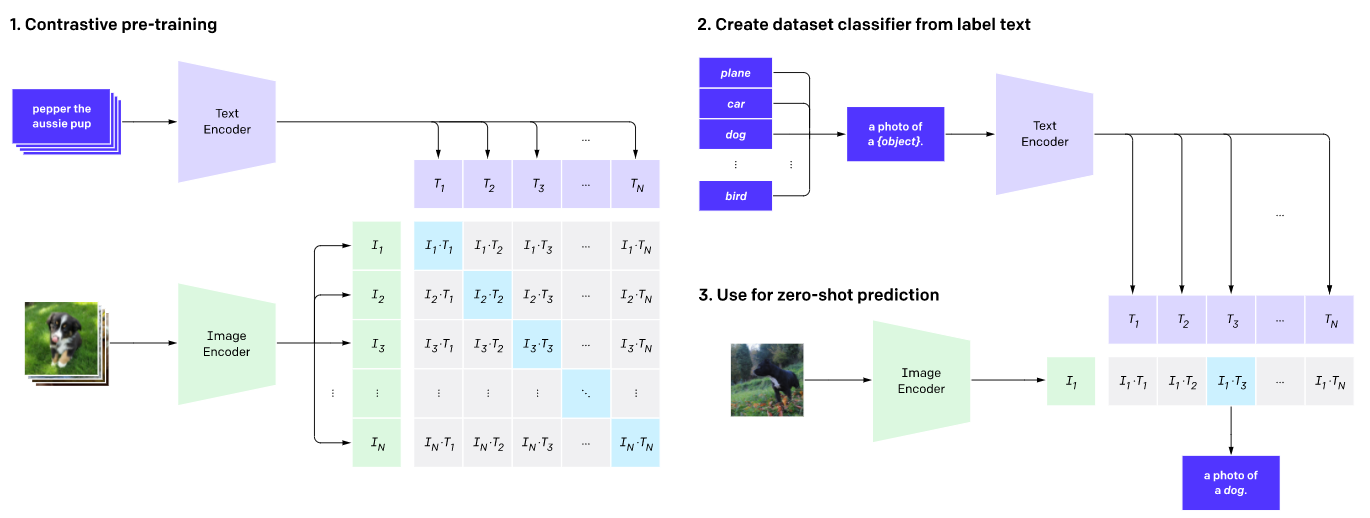 如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。
然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
如上图所示,CLIP网络工作流程: 预训练图编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。
然后,将CLIP转换为zero-shot分类器。此外,将数据集的所有分类转换为诸如“一只狗的照片”之类的标签,并预测最佳配对的图像。
SDK功能:
- 图像&文本特征向量提取
- 相似度计算
- softmax计算置信度
支持的语言列表:
- Albanian
- Amharic
- Arabic
- Azerbaijani
- Bengali
- Bulgarian
- Catalan
- Chinese (Simplified)
- Chinese (Traditional)
- Dutch
- English
- Estonian
- Farsi
- French
- Georgian
- German
- Greek
- Hindi
- Hungarian
- Icelandic
- Indonesian
- Italian
- Japanese
- Kazakh
- Korean
- Latvian
- Macedonian
- Malay
- Pashto
- Polish
- Romanian
- Russian
- Slovenian
- Spanish
- Swedish
- Tagalog
- Thai
- Turkish
- Urdu
- Vietnamese
运行例子 - ImageTextSearchExample
运行成功后,命令行应该看到下面的信息:
...# 测试文本:[INFO ] - texts: [在雪地里有两条狗, 一只猫在桌子上, 夜晚的伦敦]
# 测试图片:[INFO ] - image: src/test/resources/two_dogs_in_snow.jpg
# 向量维度:[INFO ] - Vector dimension: 512
# 生成图片向量:[INFO ] - image embeddings: [0.22221693, 0.16178696, ..., -0.06122274, 0.13340257]
# 生成文本向量 & 计算相似度:[INFO ] - text [在雪地里有两条狗] embeddings: [0.07365318, -0.011488605, ..., -0.10090914, -0.5918399][INFO ] - Similarity: 30.857948%
[INFO ] - text [一只猫在桌子上] embeddings: [0.01640176, 0.02016575, ..., -0.22862512, -0.091851026][INFO ] - Similarity: 10.379046%
[INFO ] - text [夜晚的伦敦] embeddings: [-0.19309878, -0.008406041, ..., -0.1816148, 0.12109539][INFO ] - Similarity: 14.382527%
#softmax 置信度计算:[INFO ] - texts: [在雪地里有两条狗, 一只猫在桌子上, 夜晚的伦敦][INFO ] - Label probs: [0.9999999, 1.2768101E-9, 6.995442E-8]
# "在雪地里有两条狗" 与图片相似的置信度为:0.9999999